It is no secret that I like to spend some time on investing, buying and selling stocks and index funds. I use Google sheets in order to keep track of my portfolio. Using Google sheets you can get most prices using the built-in function =GOOGLEFINANCE(<insert stockticker>), for example: =GOOGLEFINANCE("CPH:GEN"). I describe this in full detail in another post of mine.
However some markets are not supported by this for example:
- Oslo stock exchange (Norwegian stocks)
- Spotlight (Aktietorget - Sweden)
- First north (Danish stocks)
- Nordic funds
- US penny stocks
Therefore I decided to try and scrape this off external sites using ImportXml.
You can find a working examples of the below here. It contains several examples of different websites and types of stocks!
DISCLAIMER: All stocks in this blog post are examples, it should never be viewed as I am for or against any of the stocks written here.
How get stock prices using ImportXml
Note: I originally wrote this post where I primarily used marketscreener.com, I have since then switched to investing.com.
I first tried my favourite website for charts and quotes tradingview. However they use websockets and load the data asynchronously, therefore I could not scrape the data from their website as it is not present when the scraper gets the HTML. Other sites like investing.com or yahoo have the stock prices as part of the initial HTML and their sites can therefore be scraped. In this example I use investing.com. It is a good idea to find a site that has all the funds you wish to scrape, even though you of course can get them from different sites.
The fund I started with was "Danske Invest fjernøsten" (not a recommendation for or against). I used the following to import the current price:
=IMPORTXML("https://www.investing.com/etfs/danske-invest-fjernosten-indeks","//div[@data-test='instrument-header-details']/div[1]/div[1]")
The part of the HTML where the price was located, looked like the following:
<div class="flex-1" data-test="instrument-header-details">
<div class="flex flex-wrap gap-x-4 gap-y-2 items-center md:gap-6 mb-3 md:mb-0.5">
<div class="text-5xl/9 font-bold md:text-[42px] md:leading-[60px] text-[#232526]">142.55
</div>
</div>
</div>
The current price as I am writing this is "154.55" as seen in the above XML. The xpath "div[@data-test='instrument-header-details']/div[1]/div[1]" used to find the price, reads like the following: "Find any div element with the attribute data-test with the value last" and find the first child div element, then find the first child div element again. This is enough to import the data into your Google sheet.
Depending on your locale it may look odd with extra .00 after it or it looking like a completely different number. In some countries a dot (.) sets the decimal place and in others a comma (,) is used. This can cause issues if the site uses a different format than your spreadsheet. Google spreadsheets will maybe (depending on your settings) add the decimals if it believes they are missing, which gives the extra .00.
I therefore ended up trimming any ".00" and then converting the dot to a comma. This I do using the SUBSTITUTE method twice as seen below:
=SUBSTITUTE(SUBSTITUTE(IMPORTXML("https://www.investing.com/etfs/danske-invest-fjernosten-indeks","//div[@data-test='instrument-header-details']/div[1]/div[1]"); ".00"; ""); "."; ",")
Pretty? no, but that is what you get when you try to scrape data off websites. I should warn that these sort of "integrations" can break if the site you are importing from changes their HTML. If for example they change the classes or id on the element you get the price from, you will get an error. So you will often have to go back and update it, I will try to keep this page updated, if something is broken leave a comment below.
Below is the end result:
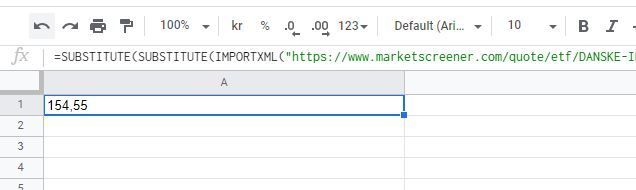
The above image is an old image from when I still used marketscreener.com.
Finding Danish index funds
The function also work for other funds, such as "Sparinvest Index Bæredygtige Japan" (not a recommendation for or against):
=IMPORTXML("
https://www.investing.com/funds/sparinvest-index-japan-growth-kl","//span[@id='last_last']")
Which gives the current price: "64.36" as I am writing this. Note the xpath //span[@id='last_last'] is different for this fund compared to the previous security. This is due to the HTML being different for these on investing.com (for some reason).
Finding Norwegian stocks
Another type of stocks not found in the Google finance API are Norwegian stocks. Prices for these can also be found using ImportXml, such as "Equinor" (not a recommendation for or against):
=IMPORTXML("
https://www.investing.com/equities/statoil","//div[@data-test='instrument-header-details']/div[1]/div[1]")
This gives the price "322" as I am writing this.
Finding stocks on Nordnet
Based on the chat below I have added the following example for getting quotes from Nordnet:
=IMPORTXML("https://www.nordnet.dk/markedet/aktiekurser/17043840-danish-aerospace-company","(//span[contains(@class,'Price__StyledPriceText-sc')])[1]")
However their classes seem auto-generated to me, so it might break. Anyway it might serve as inspiration on how to get the first occurrence of a class in the HTML.
This gives the price "5,36" for Danish Aerospace as I am writing this.
That is it
You can find a working examples of the above here.
This is my way of importing stock prices from external websites. I hope this can help you to have less to update manually in your spreadsheets! The spreadsheets of course update these values automatically. Please leave a comment down below if you found this helpful :) You may also leave a comment if you want help with scraping prices off other websites than mentioned in this post.