In this post I will describe the advantages of polling and pushing data in your applications. The patterns are used in most distributed systems. I will start by describing the polling, pushing and pulling ways of integrating systems:
Terminology
In order to defining pull, push or pull flows we need to define some terms first:
- The producer is the part that creates and owns the data.
- The consumer is the part that needs the data that the producer creates.
- Data can be any format, whether it is JSON, XML or byte arrays, it is a format that both the producer and consumer understands.
Defining the methods
Here are my definitions of pushing, polling and pulling:
Push: In this flow the producer of the data pushes it to the consumer. Whenever the producer creates or receives information it pushes it to its consumers. A simple example of this would be a HTTP PUT or POST.
Poll: In this flow the consumer requests the data from the producer. This is done at certain intervals, the consumer does not know when new data is available from the consumer. You may say that the consumer pulls the data, the distinction I make between polling and pulling is that polling is done at certain intervals to see if there is new data available. You can split this into two requests, first a quick poll request to receive a catalog of pointers to new data and secondary a pull or several pulls for the actual data. Simply put: you polled Google to get search results and you pulled this page from that catalog of data.
In this post I will be using the word "poll" for polling and retrieving data, so it is not split into both a poll and a pull request.
Pull: As already mentioned pulling is a simple request for data initiated by the consumer. For the consumer to know that there is new data the producer will somehow have to notify it (push) or the consumer will have to poll.
Examples of pushing and polling
In this section I describe the push and pull flows, starting with Push flow:
Push
For my examples I will be using HTTP / REST as most are used to that protocol. The first example is of a push flow where data is sent from the producer to the consumer by using a HTTP PUT request. All the data is within the body of the request, the consumer receives the request and returns a status code 200 OK which means it was accepted and handled:
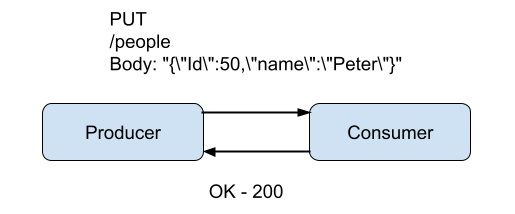
As seen in the above, the flow is quite simple and fits well with the HTTP protocol.
Poll
In the Poll flow the consumer makes a request to see if there is any new data. This can be done in different ways, one way of achieving it requires your data to be stored with an ordered unique identifier, often a timestamp or integer. This enables the consumer to make a request to see if there is anything newer than what it had previously requested. Everytime the consumer requests data it sends the identifier of the last item it received. In the example below it has reached the person with Id 49 and is now requesting anything newer, which is person 50. At the next interval where the consumer requests data it will provide the value 50. The below is a simple HTTP GET request where the same data is returned as in the push flow:
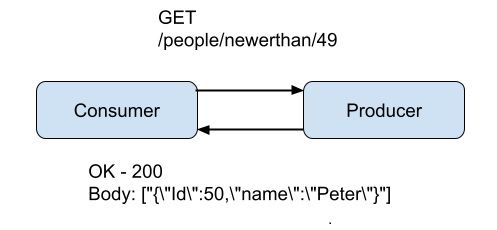
On the surface the push flow looks to be the simplest, but there is more to it. Next we will see the advantages and disadvantages of these two flows.
Advantages and disadvantages of pushing data
Advantages
- Simple to implement, all you need is an endpoint on the consumer side for the producer to call.
- Puts fault tolerance and retry logic on the producer side, so that all consumers do not need to implement a mechanism to request the data a second time, should it fail at first.
Disadvantages
- The producer needs to know all of its consumers.
- Can be hard to scale as the amount of consumers grow
Advantages and disadvantages of polling for data
Advantages
- More easily scalable as the producer does not have to know its consumers
- Simpler for the producer as it does not have to know all of its consumers. This also removes the complexity of retrying failed requests, as this complexity is for the consumer to implement.
Disadvantages
- Puts errors handling and fault tolerance issues on all the consumers instead of centralising them in the producer
- Requires the data of the producer to be in chronological order and the client to keep track of how far it is (also known as a pointer).
- Since the consumer polls at intervals it will sometimes make requests even though there is nothing new from the producer. A counter to this can be long-polling, but that has its own advantages and disadvantages.
- As the polling runs in an interval, it will never be realtime like in a push flow. Push flows can be implemented within a scheduler and run in intervals as well, but they have the possibility to push the message ASAP if needed.
Returning a key to the data
A pattern I have sometimes seen in both push and poll flows is instead of pushing or polling the data, a key and some meta data are returned instead. The key can then be used to pull the actual data. The consumer can use the meta data to decide if it needs to request the data or skip it. The size of the data has to be significant for this to make sense. If metadata is used to filter, it is often better for the consumer to provide some filters to the producer so that it only returns a subset of its data. I see these as modifications of the poll flow and do not change the advantages and disadvantages of the above.
That is it
That is it, let me know in the comments down below if you recognise any of the above patterns and if so, if I have missed anything of interest. If you have any general remarks, feel free to leave them down below as well.