There are several ways to scale software applications. The way of scaling is often thought about during the design phase of the system. I have three ways of scaling that I - and many others - often refer to. I see these as "scaling patterns" just like software has "design patterns". The three patterns can be used to scale data, servers, and services, they are mentioned in the "art of scalability" book. This is a good read for any architect or software developer who are into software architecture (I will link it at the bottom).
Scale by duplication
Scaling a system through duplication, often referred to as horizontal scaling, is a widely adopted strategy, particularly in web environments. This method involves creating exact copies of the existing system. For websites and web services, this typically means hosting the same site on multiple servers and placing a load balancer in front of them. The load balancer then directs client requests to any of the available servers, ensuring efficient distribution of the workload.
Consider the following illustration of a basic load balancer setup:
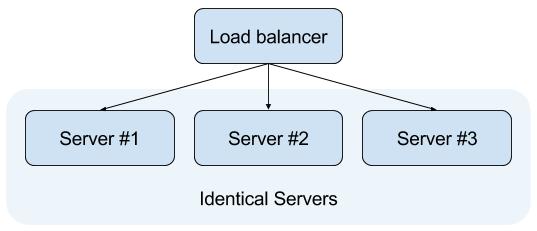
While horizontal scaling involves adding more machines to distribute the load, vertical scaling (also known as "scaling up") focuses on enhancing the performance of a single machine. This can involve upgrading hardware components like RAM or CPU, or optimizing software for better efficiency. Horizontal scaling is generally favored over vertical scaling because there's a practical limit to how much a single machine's performance can be improved. Conversely, adding more duplicates (horizontal scaling) often proves to be a more cost-effective and straightforward solution for achieving greater scalability.
Scale by splitting functionality
Another common scaling strategy involves splitting the system into multiple applications or services based on distinct functionalities. This approach treats each service as an independent application, a concept epitomized by the microservice architectural style.
The optimal way to divide a system largely depends on its specific functionalities and data model. When adopting a microservice architecture, a frequent challenge is determining the ideal granularity of each service—in other words, how small or large should microservices be? This question is equally pertinent when scaling by functional separation.
As illustrated below, consider a scenario where data handling capabilities are categorized and separated into three distinct services. In contrast to "scaling by duplication" (where each duplicate contains identical functionalities), scaling by functional decomposition involves the intentional separation of responsibilities. It is important to note that these two scaling principles are often combined. Also, splitting by functionality tends to create applications with higher internal coherence within each service.

Scale by creating subsets (Sharding)
Sharding, also known as "creating subsets," is a scaling technique that involves horizontally partitioning data. This means splitting a large dataset into smaller, independent units, where each unit, called a shard, contains a unique subset of the data. This is typically done by dividing data based on specific ranges, such as alphabetical ranges (e.g., customer names starting with A-M on one shard, N-Z on another) or numerical ranges (e.g., postal codes within a certain range on a particular shard).
In database architecture, this process is explicitly referred to as sharding, and each divided segment is a shard. Sharding becomes essential when dealing with immense volumes of data or an exceptionally high number of requests, as it distributes the workload across multiple machines, improving performance and manageability.
Below is an example of this:

A system may also be split into regions like Europe, Americas, Asia etc. This is also split by sharding, but it also serves the purpose of reducing latency.
Combine them
At all times of development it is important to keep scaling in mind. You do not have to choose one of the above. They can all be combined for different benefits.
Scaling is not everything
Before diving into scaling strategies, it's crucial to ask yourself: Why do I need to scale? What specific goals am I trying to achieve? The answers to these questions will guide your architectural decisions.
For example, are you aiming for higher availability so your system can withstand the failure of individual services? Or perhaps your services have become sluggish, and you're now seeking to improve performance and responsiveness (scalability)?
It's also important to consider consistency. Some systems can tolerate "eventual consistency," where data might not be immediately identical across all parts of the system but will eventually synchronize. Others, however, demand "strong consistency," meaning data must always be immediately consistent across the entire system.
Scaling isn't the sole consideration when designing a system or defining its architecture. Factors like data integrity, security, maintenance, and development complexity all play significant roles and must be weighed against your scaling objectives.
That is it!
I hope you liked this post, let me know what you think in the comments :)
You can find the book "the art of scalability" here (affiliate link):

Disclosure: Bear in mind that some of the links in this post are affiliate links and if you go through them to make a purchase I will earn a commission. Keep in mind that I link these companies and their products because of their quality. The decision is yours, and whether or not you decide to buy something is completely up to you.